What is LUFS and Why Should We Care?

When working with audio, there often arises a fundamental need for an objective way to measure loudness. Historically, RMS (Root Mean Square) has served this role, providing a good first-order approximation. This style of measurement quickly became ubiquitous across audio tools of all sorts. Even though it has limitations, which we’ll get into, it is a whole lot better than nothing.
Technology has advanced over time and more accurate forms of measurement have become feasible. One of the leading algorithms for this purpose today is LUFS. Its use is becoming increasingly common, especially given its adoption by many popular streaming platforms.
LUFS stands for “Loudness Units Full Scale.” It measures perceived audio loudness over time. This standard was introduced to address the limitations of RMS and Peak measurements in gauging “loudness.” In this article, we’ll demystify the LUFS algorithm, breaking it down step by step. While the process isn’t overly complex, it represents a significant improvement over the RMS or Peak algorithms.
To start with, let’s get an understanding of what RMS is and come to understand its limitations better.
RMS (“Root Mean Square”)
Let’s start from first principles. We’re looking to measure the “loudness” of an audio signal. We’ll start with a very simple audio signal: the sine wave. If we wanted to know the “loudness” of a single amplitude in this waveform, we could simply calculate its absolute value. This way both the positive and negative amplitudes below are counted the same:
Given the above, it seems reasonable that the loudness of the entire waveform would be the average absolute value of all amplitudes. In other words we sum all the absolute values, shown below, and then divide by the number of samples. This will give us a rough measure of the “loudness” of the entire waveform.
RMS takes this simple algorithm and improves it one step further. To more accurately model how human audio perception works, we would like to weigh the higher amplitudes stronger than the lower amplitudes. There’s an easy way to do that mathematically, which is to square the individual amplitude values.
Since squaring also happens to remove the sign (+/-) of the amplitude, we no longer need to take the absolute value. So all told, we just need to square each amplitude, add them up, divide by the total number of amplitude samples, then take the square root.
In the visual below, the individual amplitudes have been squared. Notice that the lower amplitudes have decreased in their relative value. This results in RMS weighing those amplitudes less than the larger amplitudes, which is more in line with human auditory perception.
K-weighting
Moving on from RMS, the first aspect of LUFS we should understand is the idea of K-weighting. In principle, this is a way to capture the fact that human hearing doesn’t respond to all frequencies the same. Some frequencies tend to sound louder than others, so we should compensate for that fact for a more accurate measure of loudness.
The LUFS standard gives us a set of filter coefficients to help account for this aspect of human hearing. The frequency response of these filters can be seen below, from the LUFS specification:
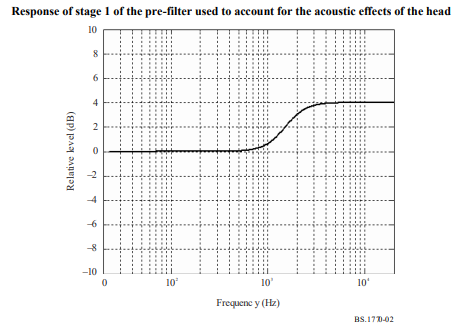
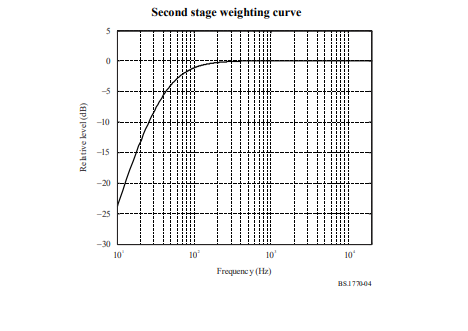
These filters are applied prior to summing the squares of amplitudes, giving an improvement over RMS by weighing frequencies in natural proportion. This feature of LUFS helps make APU Loudness Compressor sound more transparent when compared to a traditional RMS style compressor.
Channel weighting

In order to better support multi-channel audio formats, LUFS also allows for different channel types to be weighed differently. This improves the perceptual accuracy further when compared to RMS, as it reflects the positioning and relative loudness of various sound system speakers. Certain channels, for example LFE (Low-Frequency Effects), are disabled entirely.
The channel weighting feature of LUFS helps make APU Loudness Compressor particularly well suited for usage with Dolby Atmos®
and other multi-channel audio formats.
Momentary / Short-Term
Typically for LUFS, audio is broken down into overlapping sections of either 0.4 or 3.0 seconds. These lengths of time correspond to Momentary and Short-Term respectively. The choice of which is appropriate depends on how responsive you need the metering to be. Momentary is more responsive, capturing moment-by-moment dynamics better, while short-term uses a longer duration to capture the large scale dynamics.
Integrated Loudness / Gating
In addition to these momentary and short-term measurements, LUFS has the concept of an integrated loudness. This measurement is used to capture the loudness of an entire waveform (beyond just 0.4 or 3.0 seconds). In its simplest form, this would essentially just be an average of all momentary measurements across the entire waveform. But LUFS also includes some additional logic to help make this a more robust measurement of perceived loudness.
Across the entire waveform, measurements below the LUFS threshold of -70 LUFS are discarded. These are considered to be too quiet to matter. Additionally, once the preliminary integrated loudness is calculated, another LUFS threshold is calculated as 10 LUFS below the average of all measurements. Measurements below this new threshold are then also discarded, which has the effect of adapting the gate to the actual loudness content of the waveform.
In the next article, we’ll dig into a recent performance optimization which reduced CPU usage for both APU Loudness Meter and APU Loudness Compressor by an order of magnitude.
- Back to the top -
- Permalink -